Synthetic Tabular Data
Introduction
Goal: Generate synthetic data sets replacing the original tabular data during the data-exploration phase. Differential Privacy is great for releasing results from queries about sensitive datasets in a privacy-preserving way. However, DP's privacy strengths can turn into a problem when it comes to learn more about unknown data sets. In such data exploration phases the privacy budget introduced by DP can limit the data exploration and data engineering tasks. Synthetic data to the rescue. If we would be able to automatically produce high-quality synthetic data that does not contain any private information the data analysts would be able to perform queries on this data without limitations. To preserver DQ0's strong privacy guarantees the synthetization itself will be computed with differential privacy applied.
During synthetization a certain amount of privacy budget is spent once. Subsequent queries on the synthetic data won't consume any more budget. Due to the synthetization process the quality of the synthetic data is high but not comparable to that of the original data set. Therefore, the proposal is to use the synthetic data only for the data exploration and query development phases and then switch to the Private SQL queries for "real" reporting and analysis tasks.
With synthetic data we could:
- perform an unlimited number of queries
- use the whole SQL query syntax (no restriction on the SQL grammar or the form of the SQL queries)
Method
See the following thesis for an overview of general challenges with the generation of synthetic tabular data: Synthesizing Tabular Data using Conditional GAN, Lei Xu, Massachusetts Institute of Technology, 2020
Data-generating task
- generative models: learn distribution of the (training) data p(x) to tell whether a given instance is likely
- sample from learnt distribution to accomplish data-generating tasks (synthesise data)
- learning the exact data distribution is usually not practical (Bayesian networks)
- actually one does not need to explicitly model the distribution (i.e., return probs)
- mimicking that distribution is enough: generate convincing data looking like they are drawn from that distribution
- convincing == similar to the real (training) data (GANs)
Generative models based on Generative Adversarial Networks (GANs)
- adversarial game approach rather than likelihood maximization for training generative model
- game between data generator and data discriminator
- impressive results on some tasks (most "celebrated" results about image generation)
- difficult to use:
- architecture
- hyper-parameters initialization
- unstable behaviour of GAN training. Known issues:
- vanishing gradients if discriminator gets too good. Intuitively: if discriminator is too good, generator can never fool it, so cannot learn from "winning" examples
- mode collapse. The generator is always trying to find the output that seems most plausible to the discriminator. Once found, keep returning it...
- convergence not a steady state. If the generator gets so good that it succeeds perfectly, then the discriminator has 50% accuracy… Learning signal not anymore informative
- limitations:
- GANs designed for generating continuous values, difficulty with discrete data. Even worse with mixture of continuous and discrete data.
- prone to privacy attacks (DP-GANs)
Good starting point: Differentially Private Mixed-Type Data Generation For Unsupervised Learning, 2019, Tantipongpipat et al.
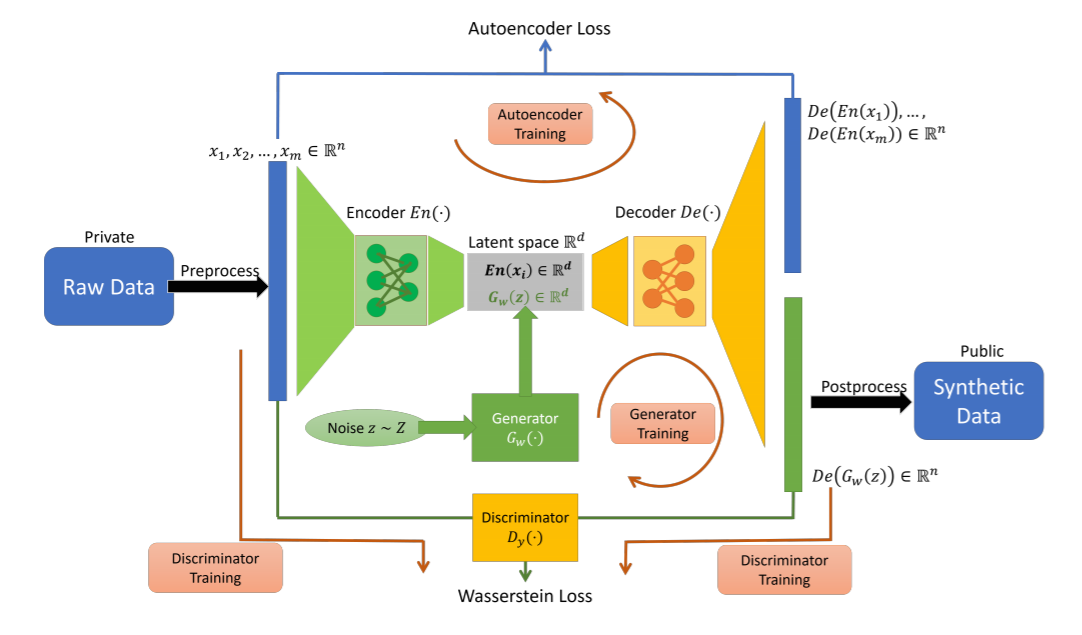
Figure 1. Summary of the DP AutoGAN algorithmic framework.
Pre- and post-processing (in black) are assumed to be public knowledge. Encoder and generator (in green) are trained without noise injection Decoder and discriminator (in yellow) are trained with noise. The four red arrows indicate how data are forwarded for each training: autoencoder training, generator training, and discriminator training. After training, the generator and decoder (but not encoder) are released to the public to generate synthetic data.