Census Dataset Example
The Census Adult dataset, also known as the "Census Income" dataset, has been extracted by Barry Becker from the 1994 Census database. It is used a standard machine learning playground. The task is to predict whether income exceeds $50K/yr based on census data.
Setting up the dataset
Login to DQ0 as a "Data Owner" user to set up this dataset for usage on the DQ0 platform. Start by exploring the dataset in a CSV viewer of your choice.
The column definitions are as follows
| Column | Type or Values |
|---|---|
| age | continuous |
| workclass | Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked |
| fnlwgt | continuous |
| education | Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool |
| education-num | continuous |
| marital-status | Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse |
| occupation | Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces |
| relationship | Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried |
| race | White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black |
| sex | Female, Male |
| capital-gain | continuous |
| capital-loss | continuous |
| hours-per-week | continuous |
| native-country | United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands |
Now use the DQ0 dataset editor to register and define this dataset to the platform.
Specifiy the source of the dataset as a file path to the CSV:
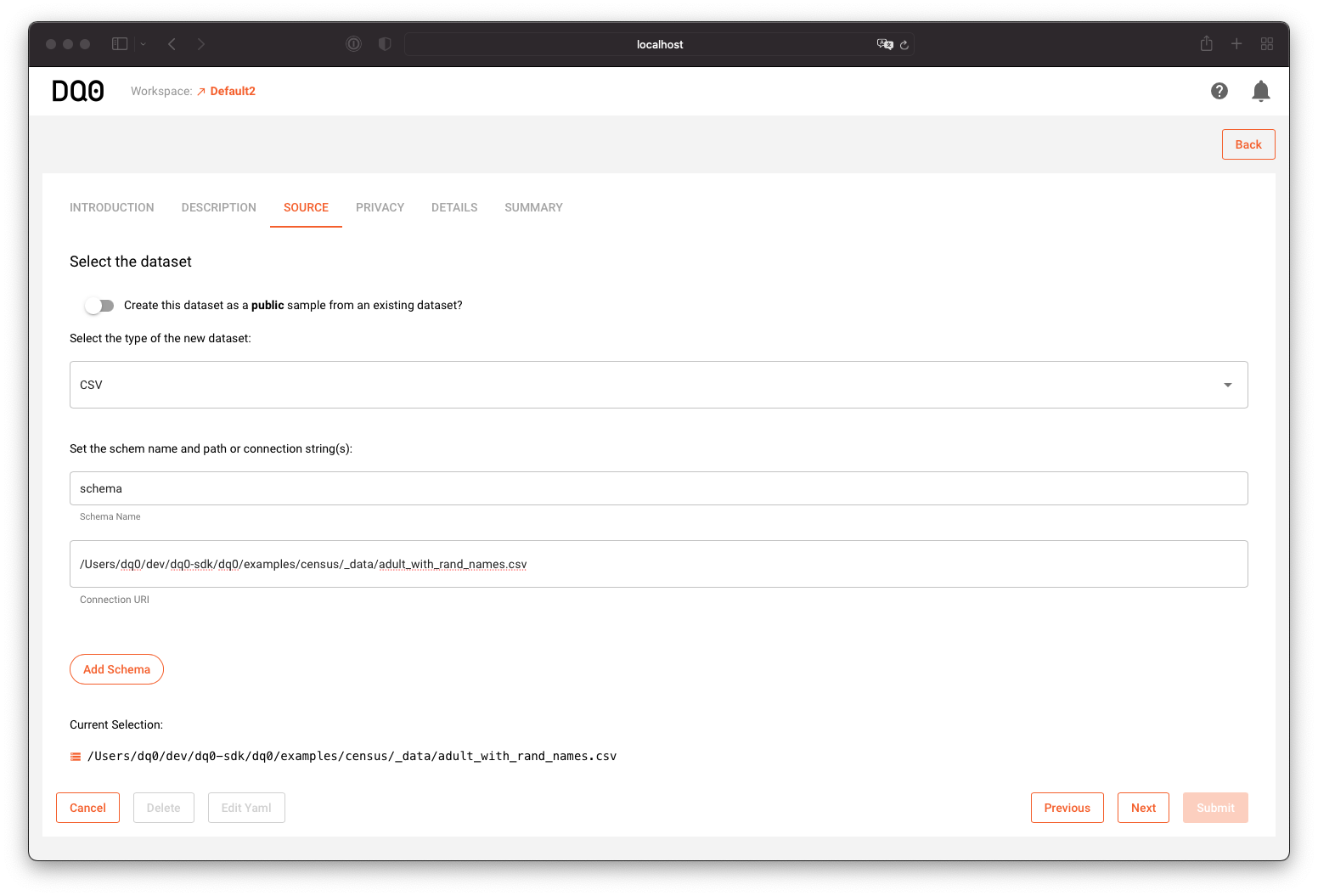
And define the properties according to the column descriptions above:
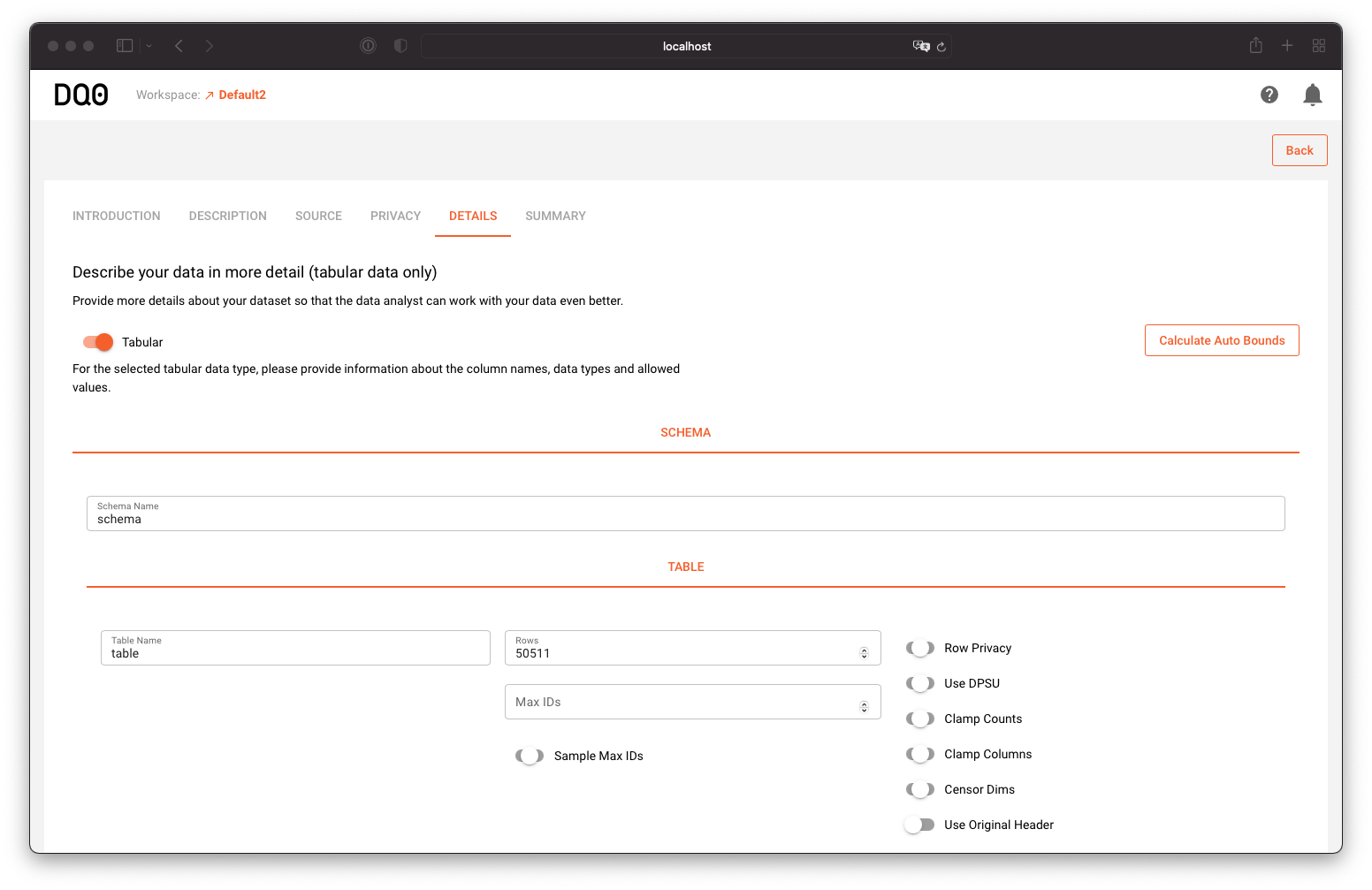
A valid metadata definition for the Census dataset, that can be inspected or edited in the "Summary" tab of the data set editor, looks like this:
description: 'This data was extracted from the 1994 Census bureau database by Ronny Kohavi and Barry Becker (Data Mining and Visualization, Silicon Graphics). A set of reasonably clean records was extracted using the following conditions: ((AAGE>16) && (AGI>100) && (AFNLWGT>1) && (HRSWK>0)). The prediction task is to determine whether a person makes over $50K a year'
name: Adult Census Income
type: CSV
privacy_column: fnlwgt
schema:
connection: ../dq0-sdk/dq0/examples/census/_data/adult_with_rand_names.csv
table:
rows: 50511
age:
is_feature: true
lower: 19
synthesizable: true
type: int
upper: 59
capital-gain:
is_feature: true
lower: 0
synthesizable: true
type: int
upper: 0
capital-loss:
is_feature: true
lower: 0
synthesizable: true
type: int
upper: 0
education:
cardinality: 16
is_feature: true
synthesizable: true
type: string
education-num:
is_feature: true
lower: 6
synthesizable: true
type: int
upper: 14
fnlwgt:
is_feature: true
lower: 39824
synthesizable: true
type: int
upper: 334679
hours-per-week:
is_feature: true
lower: 20
synthesizable: true
type: int
upper: 60
income:
cardinality: 2
is_target: true
synthesizable: true
type: string
marital-status:
cardinality: 7
is_feature: true
synthesizable: true
type: string
na_values:
capital-gain: 99999
capital-loss: 99999
hours-per-week: 99
native-country: '?'
occupation: '?'
workclass: '?'
native-country:
cardinality: 42
is_feature: true
synthesizable: true
type: string
occupation:
cardinality: 15
is_feature: true
synthesizable: true
type: string
race:
cardinality: 5
is_feature: true
synthesizable: true
type: string
relationship:
cardinality: 6
is_feature: true
synthesizable: true
type: string
sex:
cardinality: 2
is_feature: true
synthesizable: true
type: string
workclass:
cardinality: 9
is_feature: true
synthesizable: true
type: string
skipinitialspace: true
use_original_header: false
header_columns:
- age
- workclass
- fnlwgt
- education
- education-num
- marital-status
- occupation
- relationship
- race
- sex
- capital-gain
- capital-loss
- hours-per-week
- native-country
- income
Learn more about editing datasets here: Datasets
Working with the data
To work with this dataset, now login as a "Data Science" user to DQ0.
You can query the dataset with SQL statements or build a machine learning model to solve the above mentioned prediction task. This example will continue with the latter, if you want to learn more about SQL queries, visit the SQL Queries documentation.
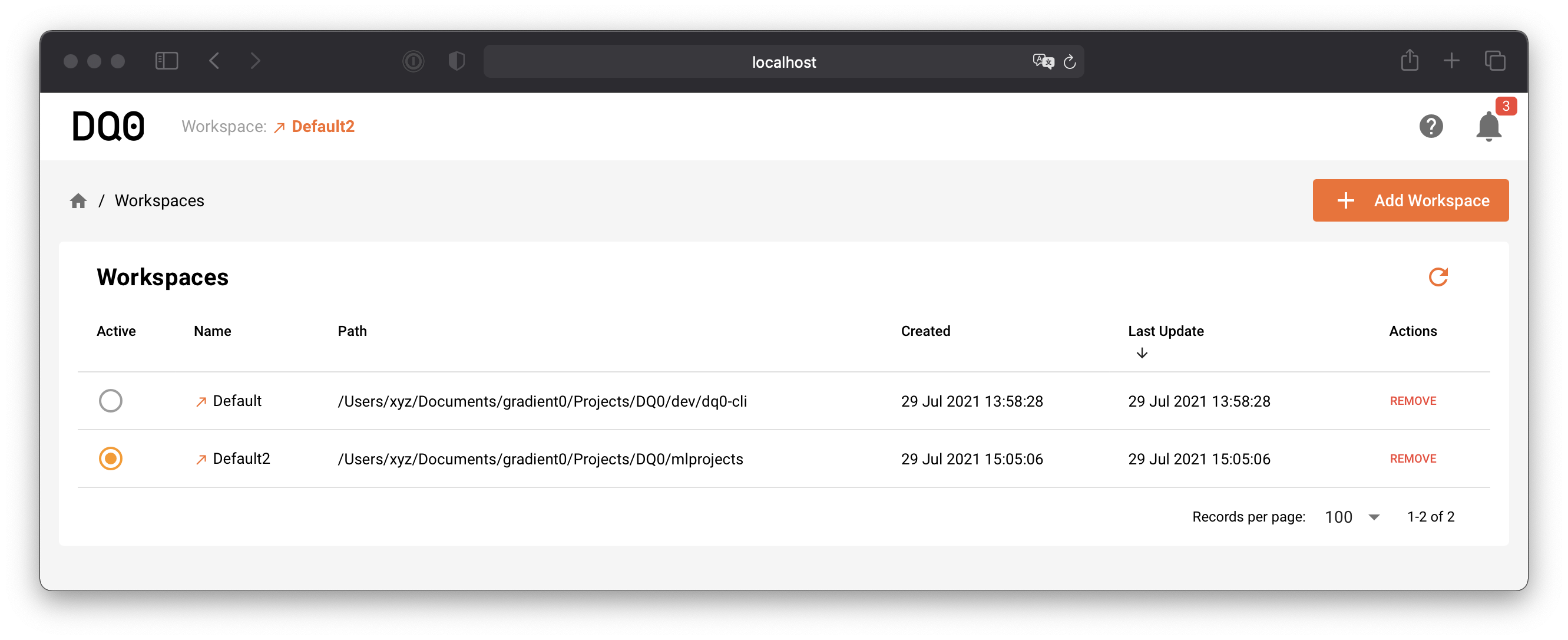
Start by selecting a workspace:
The Machine Learning Project
Create a project folder with the MLProject template wizard by clicking on the button "Add Project From Template" in the workspace screen. The template chooser looks as follows:
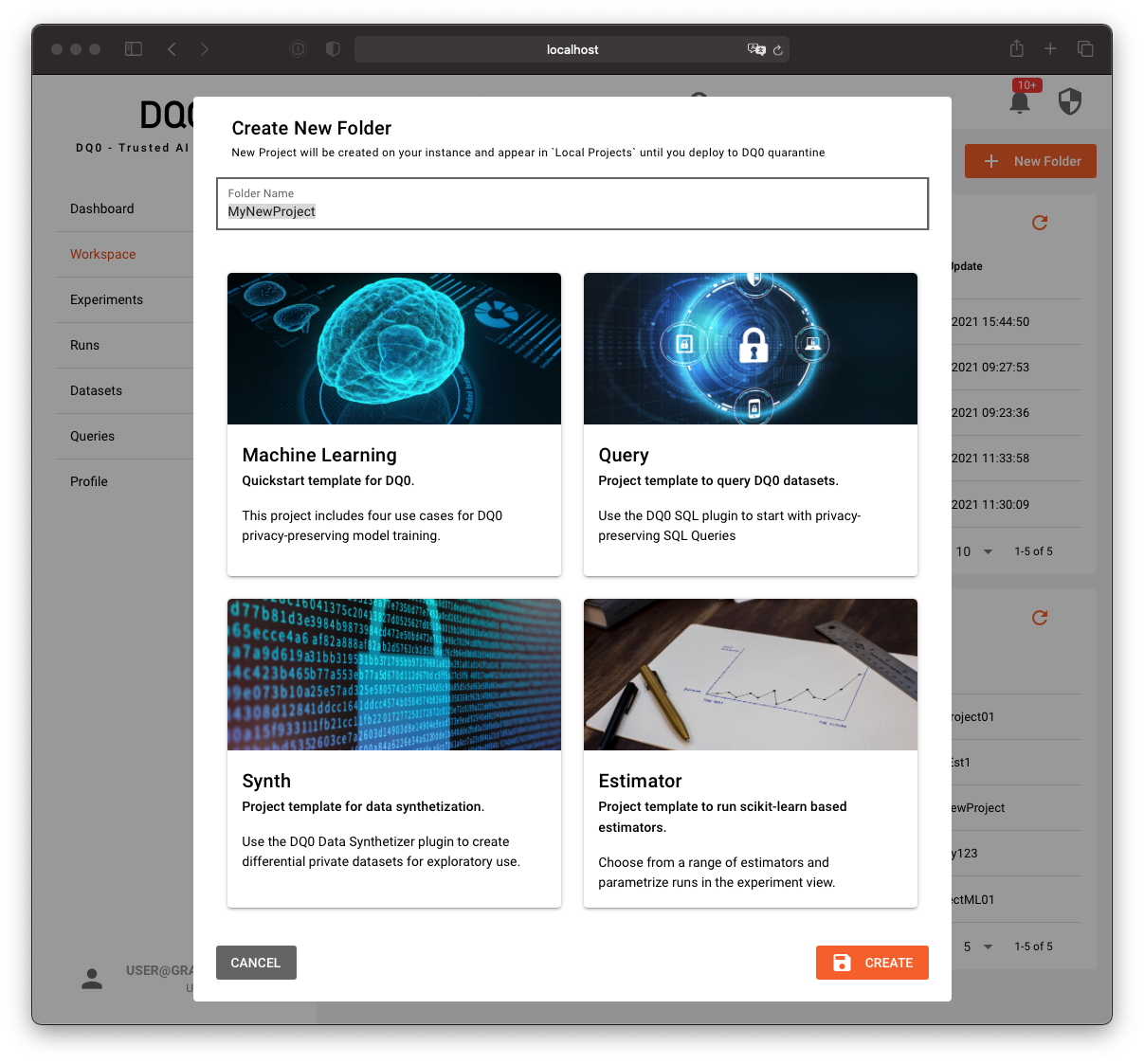
Select the Machine Learning template.
Now open the project folder inside your local workspace directory to edit the model code in an editor or IDE of your choise. With Visual Studio Code this might look like this:
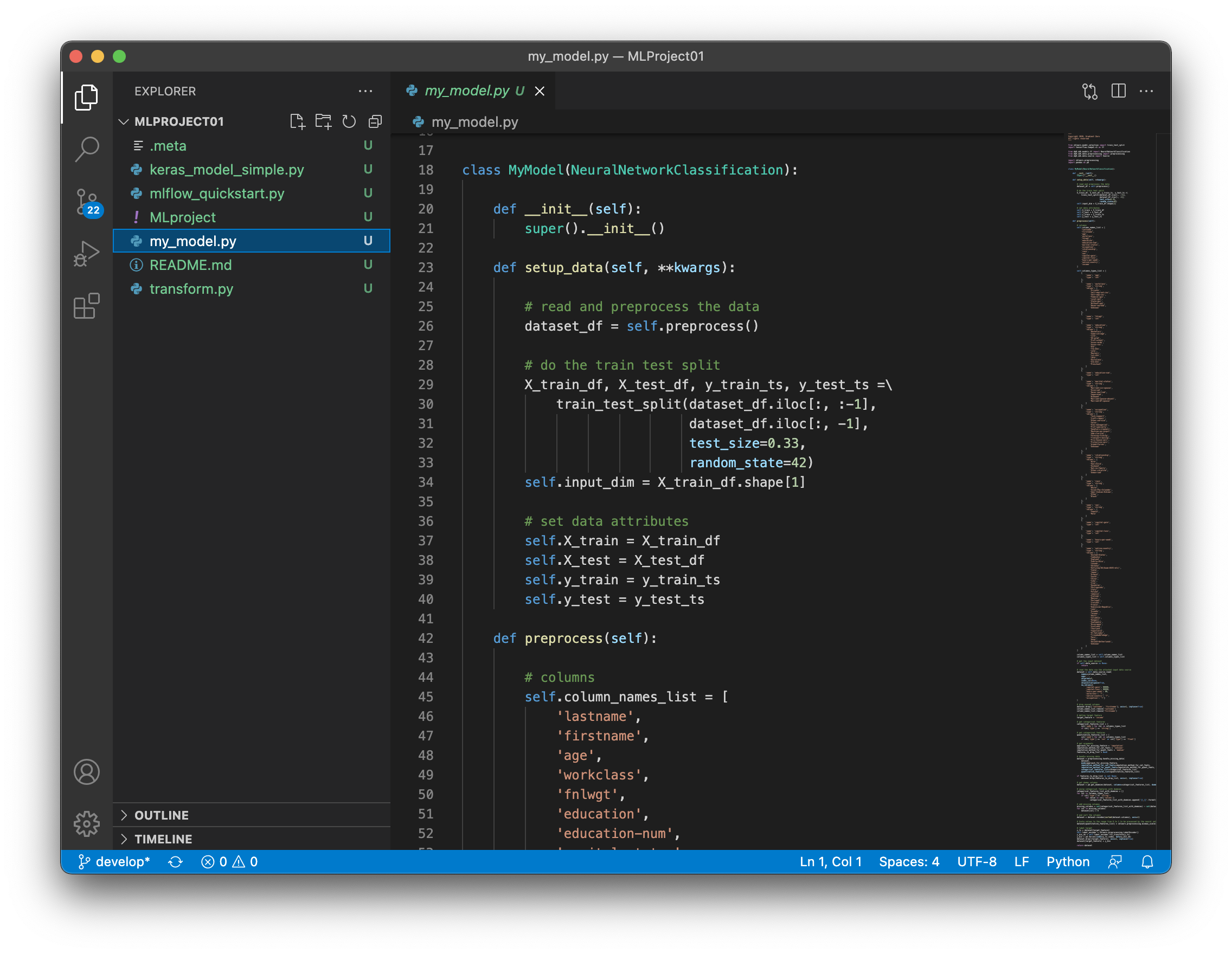
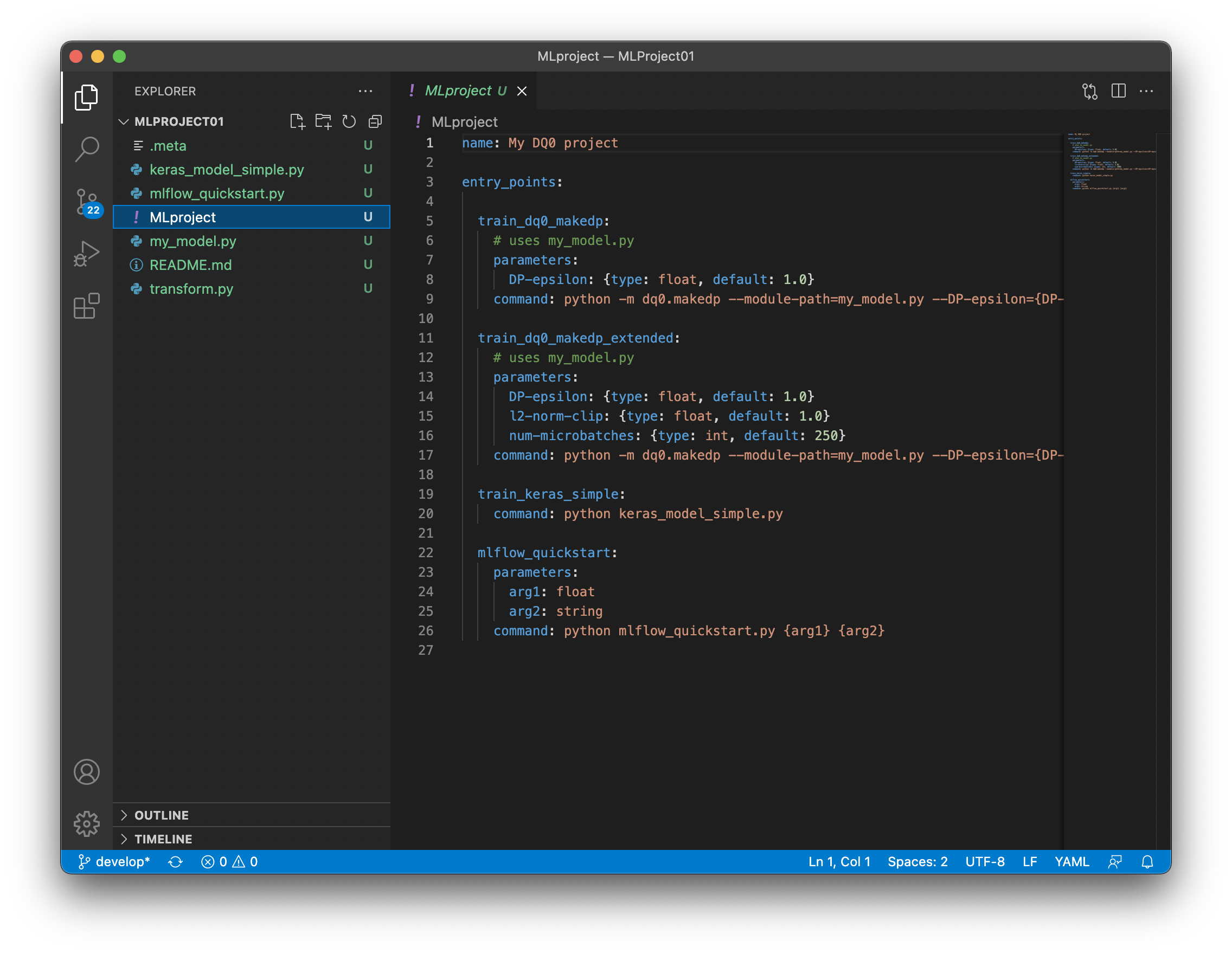
The project folder contains an MLProject file that defines your entry points to model training and other DQ0 runs. For more information on runs, see Runs & Experiments.
The Census Prediction Model
Find the complete machine learning model code for the prediction task example below:
# -*- coding: utf-8 -*-
"""
Copyright 2020, Gradient Zero
All rights reserved
"""
from sklearn.model_selection import train_test_split
import tensorflow.compat.v1 as tf
from dq0.sdk.models.tf import NeuralNetworkClassification
from dq0.sdk.data.preprocessing import preprocessing
from dq0.sdk.data.source import Source
import sklearn.preprocessing
import pandas as pd
class MyModel(NeuralNetworkClassification):
def __init__(self):
super().__init__()
def setup_data(self, **kwargs):
# read and preprocess the data
dataset_df = self.preprocess()
# do the train test split
X_train_df, X_test_df, y_train_ts, y_test_ts =\
train_test_split(dataset_df.iloc[:, :-1],
dataset_df.iloc[:, -1],
test_size=0.33,
random_state=42)
self.input_dim = X_train_df.shape[1]
# set data attributes
self.X_train = X_train_df
self.X_test = X_test_df
self.y_train = y_train_ts
self.y_test = y_test_ts
def preprocess(self):
# columns
self.column_names_list = [
'lastname',
'firstname',
'age',
'workclass',
'fnlwgt',
'education',
'education-num',
'marital-status',
'occupation',
'relationship',
'race',
'sex',
'capital-gain',
'capital-loss',
'hours-per-week',
'native-country',
'income'
]
self.columns_types_list = [
{
'name': 'age',
'type': 'int'
},
{
'name': 'workclass',
'type': 'string',
'values': [
'Private',
'Self-emp-not-inc',
'Self-emp-inc',
'Federal-gov',
'Local-gov',
'State-gov',
'Without-pay',
'Never-worked',
'Unknown'
]
},
{
'name': 'fnlwgt',
'type': 'int'
},
{
'name': 'education',
'type': 'string',
'values': [
'Bachelors',
'Some-college',
'11th',
'HS-grad',
'Prof-school',
'Assoc-acdm',
'Assoc-voc',
'9th',
'7th-8th',
'12th',
'Masters',
'1st-4th',
'10th',
'Doctorate',
'5th-6th',
'Preschool'
]
},
{
'name': 'education-num',
'type': 'int'
},
{
'name': 'marital-status',
'type': 'string',
'values': [
'Married-civ-spouse',
'Divorced',
'Never-married',
'Separated',
'Widowed',
'Married-spouse-absent',
'Married-AF-spouse'
]
},
{
'name': 'occupation',
'type': 'string',
'values': [
'Tech-support',
'Craft-repair',
'Other-service',
'Sales',
'Exec-managerial',
'Prof-specialty',
'Handlers-cleaners',
'Machine-op-inspct',
'Adm-clerical',
'Farming-fishing',
'Transport-moving',
'Priv-house-serv',
'Protective-serv',
'Armed-Forces',
'Unknown'
]
},
{
'name': 'relationship',
'type': 'string',
'values': [
'Wife',
'Own-child',
'Husband',
'Not-in-family',
'Other-relative',
'Unmarried'
]
},
{
'name': 'race',
'type': 'string',
'values': [
'White',
'Asian-Pac-Islander',
'Amer-Indian-Eskimo',
'Other',
'Black'
]
},
{
'name': 'sex',
'type': 'string',
'values': [
'Female',
'Male'
]
},
{
'name': 'capital-gain',
'type': 'int'
},
{
'name': 'capital-loss',
'type': 'int'
},
{
'name': 'hours-per-week',
'type': 'int'
},
{
'name': 'native-country',
'type': 'string',
'values': [
'United-States',
'Cambodia',
'England',
'Puerto-Rico',
'Canada',
'Germany',
'Outlying-US(Guam-USVI-etc)',
'India',
'Japan',
'Greece',
'South',
'China',
'Cuba',
'Iran',
'Honduras',
'Philippines',
'Italy',
'Poland',
'Jamaica',
'Vietnam',
'Mexico',
'Portugal',
'Ireland',
'France',
'Dominican-Republic',
'Laos',
'Ecuador',
'Taiwan',
'Haiti',
'Columbia',
'Hungary',
'Guatemala',
'Nicaragua',
'Scotland',
'Thailand',
'Yugoslavia',
'El-Salvador',
'Trinadad&Tobago',
'Peru',
'Hong',
'Holand-Netherlands',
'Unknown'
]
}
]
column_names_list = self.column_names_list
columns_types_list = self.columns_types_list
# get the input dataset
if self.data_source is None:
return
# read the data via the attached input data source
dataset = self.data_source.read(
names=column_names_list,
sep=',',
skiprows=1,
index_col=None,
skipinitialspace=True,
na_values={
'capital-gain': 99999,
'capital-loss': 99999,
'hours-per-week': 99,
'workclass': '?',
'native-country': '?',
'occupation': '?'}
)
# drop unused columns
dataset.drop(['lastname', 'firstname'], axis=1, inplace=True)
column_names_list.remove('lastname')
column_names_list.remove('firstname')
# define target feature
target_feature = 'income'
# get categorical features
categorical_features_list = [
col['name'] for col in columns_types_list
if col['type'] == 'string']
# get categorical features
quantitative_features_list = [
col['name'] for col in columns_types_list
if col['type'] == 'int' or col['type'] == 'float']
# get arguments
approach_for_missing_feature = 'imputation'
imputation_method_for_cat_feats = 'unknown'
imputation_method_for_quant_feats = 'median'
features_to_drop_list = None
# handle missing data
dataset = preprocessing.handle_missing_data(
dataset,
mode=approach_for_missing_feature,
imputation_method_for_cat_feats=imputation_method_for_cat_feats,
imputation_method_for_quant_feats=imputation_method_for_quant_feats, # noqa: E501
categorical_features_list=categorical_features_list,
quantitative_features_list=quantitative_features_list)
if features_to_drop_list is not None:
dataset.drop(features_to_drop_list, axis=1, inplace=True)
# get dummy columns
dataset = pd.get_dummies(dataset, columns=categorical_features_list, dummy_na=False)
# unzip categorical features with dummies
categorical_features_list_with_dummies = []
for col in columns_types_list:
if col['type'] == 'string':
for value in col['values']:
categorical_features_list_with_dummies.append('{}_{}'.format(col['name'], value))
# add missing columns
missing_columns = set(categorical_features_list_with_dummies) - set(dataset.columns)
for col in missing_columns:
dataset[col] = 0
# and sort the columns
dataset = dataset.reindex(sorted(dataset.columns), axis=1)
# Scale values to the range from 0 to 1 to be precessed by the neural network
dataset[quantitative_features_list] = sklearn.preprocessing.minmax_scale(dataset[quantitative_features_list])
# label target
y_ts = dataset[target_feature]
self.label_encoder = sklearn.preprocessing.LabelEncoder()
y_bin_nb = self.label_encoder.fit_transform(y_ts)
y_bin = pd.Series(index=y_ts.index, data=y_bin_nb)
dataset.drop([target_feature], axis=1, inplace=True)
dataset[target_feature] = y_bin
return dataset
def setup_model(self, **kwargs):
self.model = tf.keras.Sequential([
tf.keras.layers.Input(self.input_dim),
tf.keras.layers.Dense(10, activation='tanh'),
tf.keras.layers.Dense(10, activation='tanh'),
tf.keras.layers.Dense(2, activation='softmax')])
self.optimizer = 'Adam'
# To set optimizer params, self.optimizer = optimizer instance
# rather than string, with params values passed as input to the class
# constructor. E.g.:
#
# import tensorflow
# self.optimizer = tensorflow.keras.optimizers.Adam(
# learning_rate=0.015)
#
self.epochs = 10
self.batch_size = 250
self.metrics = ['accuracy']
self.loss = tf.keras.losses.SparseCategoricalCrossentropy()
# As an alternative, define the loss function with a string
Starting a run
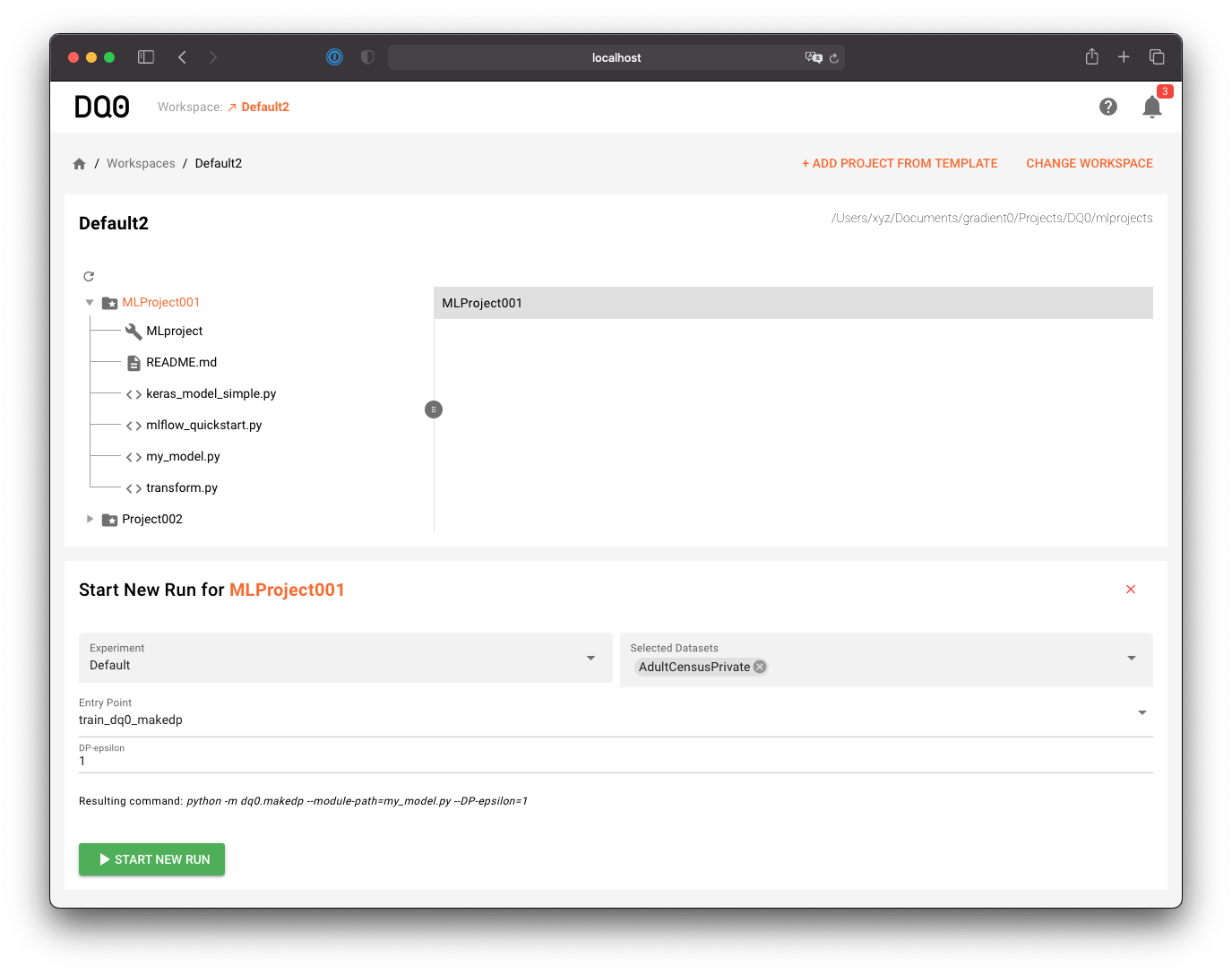
Now click on the "Prepare New Run With This Folder" button in the workspace view to prepare a new run with the selected folder's content:
A new component below will show up. Select a dataset to use for the run, an entry point (the script to run), parametrize the run and start it with a click on Start New Run:
Inspecting run status
Click on the run or navigate to the run through the "Runs" or "Experiment" screens to inspect the results. Go to the "Files" tab to browse the model files. You can inspect additional model information or - if approved - download the model files.
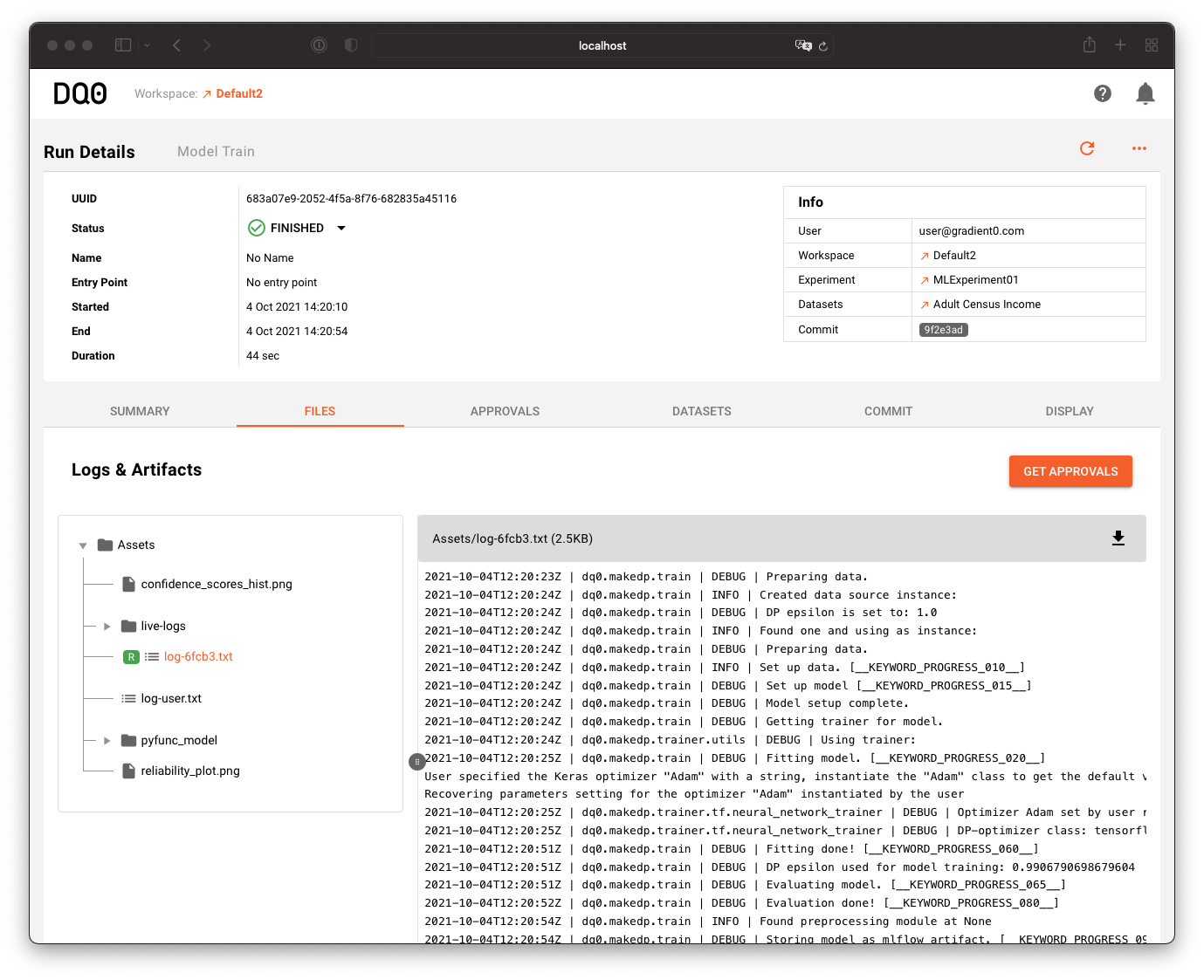
Monitor the activity & release results
On the "Data Owner" side you can inspect the latest activity and manage approvals if a run result is requested to be released by a "Data Science" user.
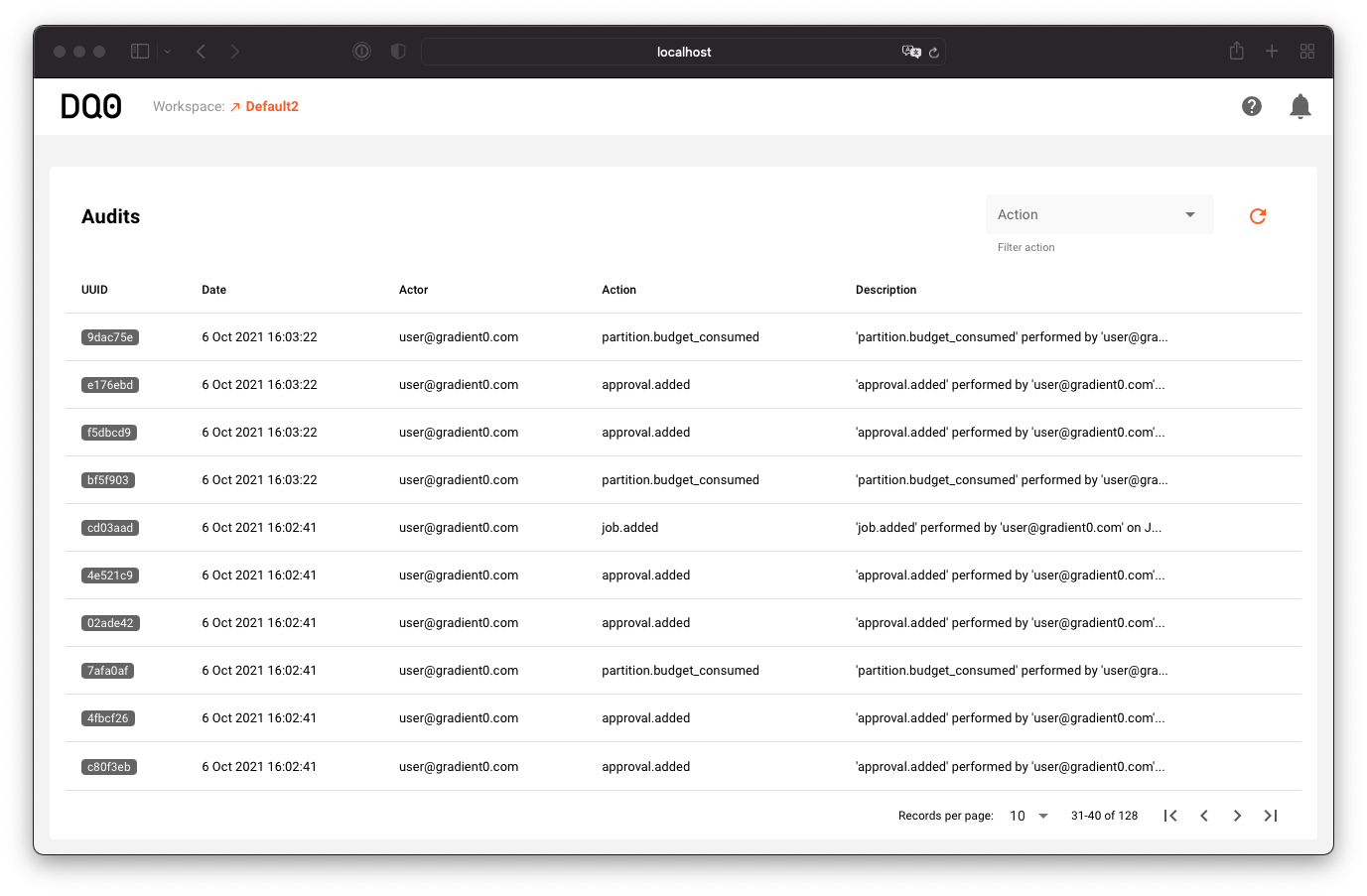
Jupyter Notebook Quickstart
Please have a look at the Quickstart Jupyter Notebook for a getting started guide:
https://github.com/gradientzero/dq0-sdk/blob/master/notebooks/DQ0SDK-Quickstart.ipynb