Runs & Experiments
Workspace
DQ0 organizes your analytics and machine learning workflows, but not your local code. It is highly recommended to use a code repository with a version control system like git to manage your code on an individual and team basis. To start using your code in DQ0 select a Workspace, that is a local folder acting as the root node of your current code project environment. Click on the link next to "Workspace" in the top bar to manage your workspace selection:
Use "Change Workspace" on the upper right to change your local workspace folder.
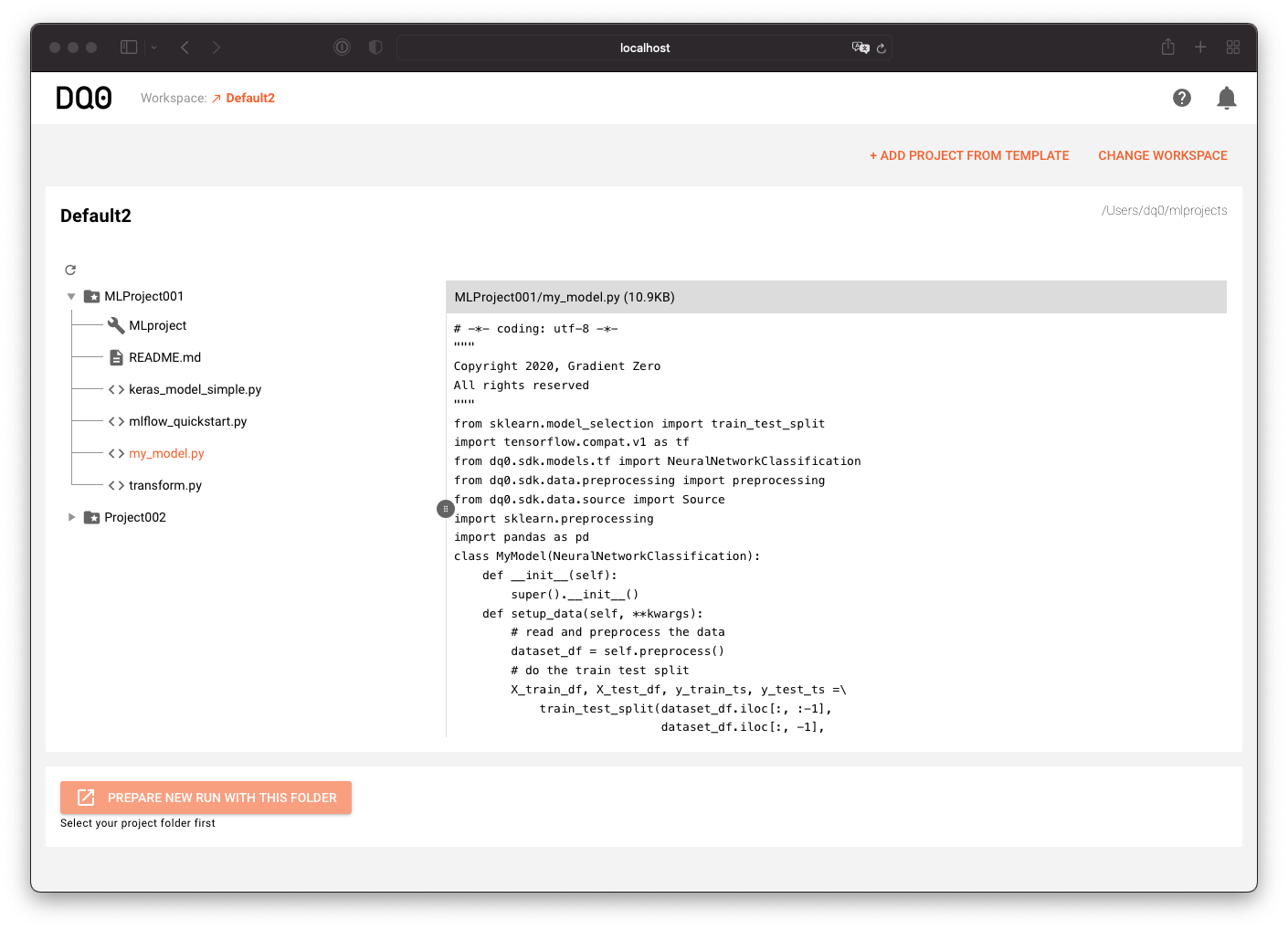
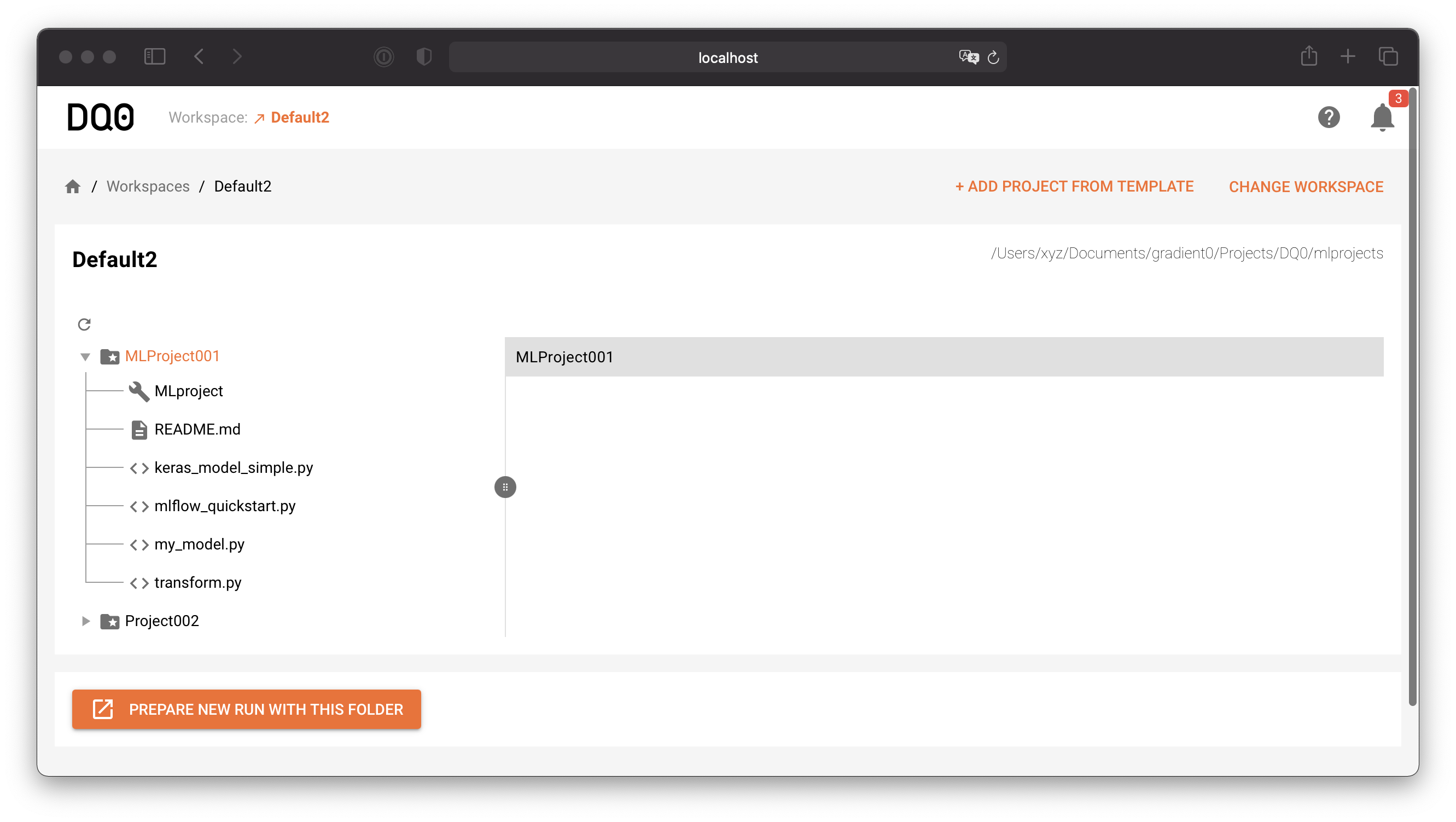
Browse the files of your workspace with the file browser as shown above.
Runs
To start a new run navigate to a folder containing an MLProject file or create such a folder with the MLProject template wizard by clicking on the button "Add Project From Template" in the above workspace screen. The template chooser looks as follows:
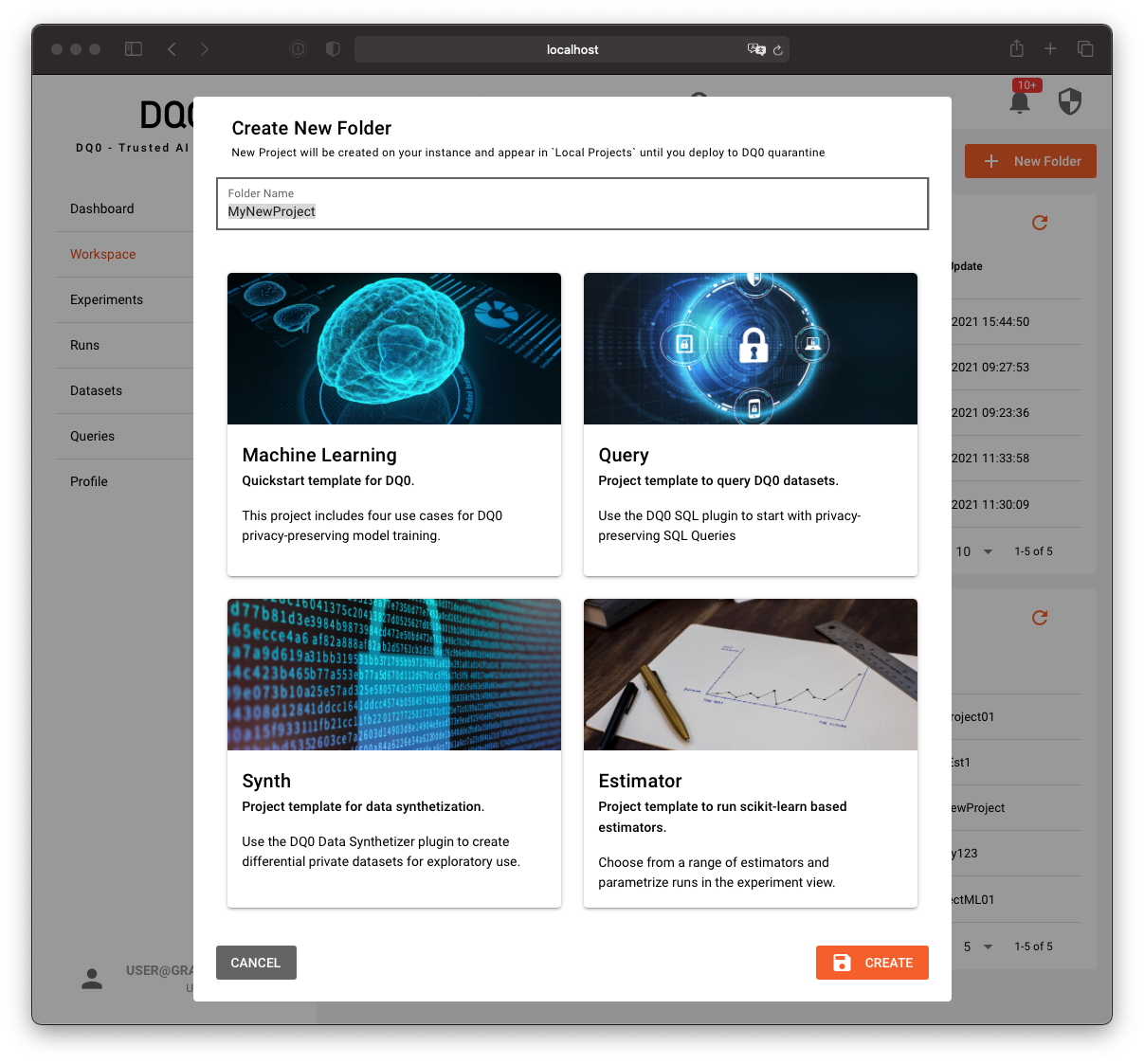
There are four pre-built templates that you can use as a starting point for DQ0 runs:
Machine Learningis a general purpose quickstart template for DQ0 machine learning development.Estimatoris a template containing a long list of pre-defined, parametrizable machine learning estimators.Queryis a template for scripted SQl queries on DQ0 managed structured data.Synthis a special template to generate synthetic data from DQ0 managed datasets.
Once you selected a folder containing an MLProject file (e.g. a folder created with the template wizard) you can lick on the "Prepare New Run With This Folder" button below the file explorer to prepare a new run with the selected folder's content:
A new component below will show up. Select a dataset to use for the run, an entry point (the script to run), parametrize the run and start it with a click on Start New Run:
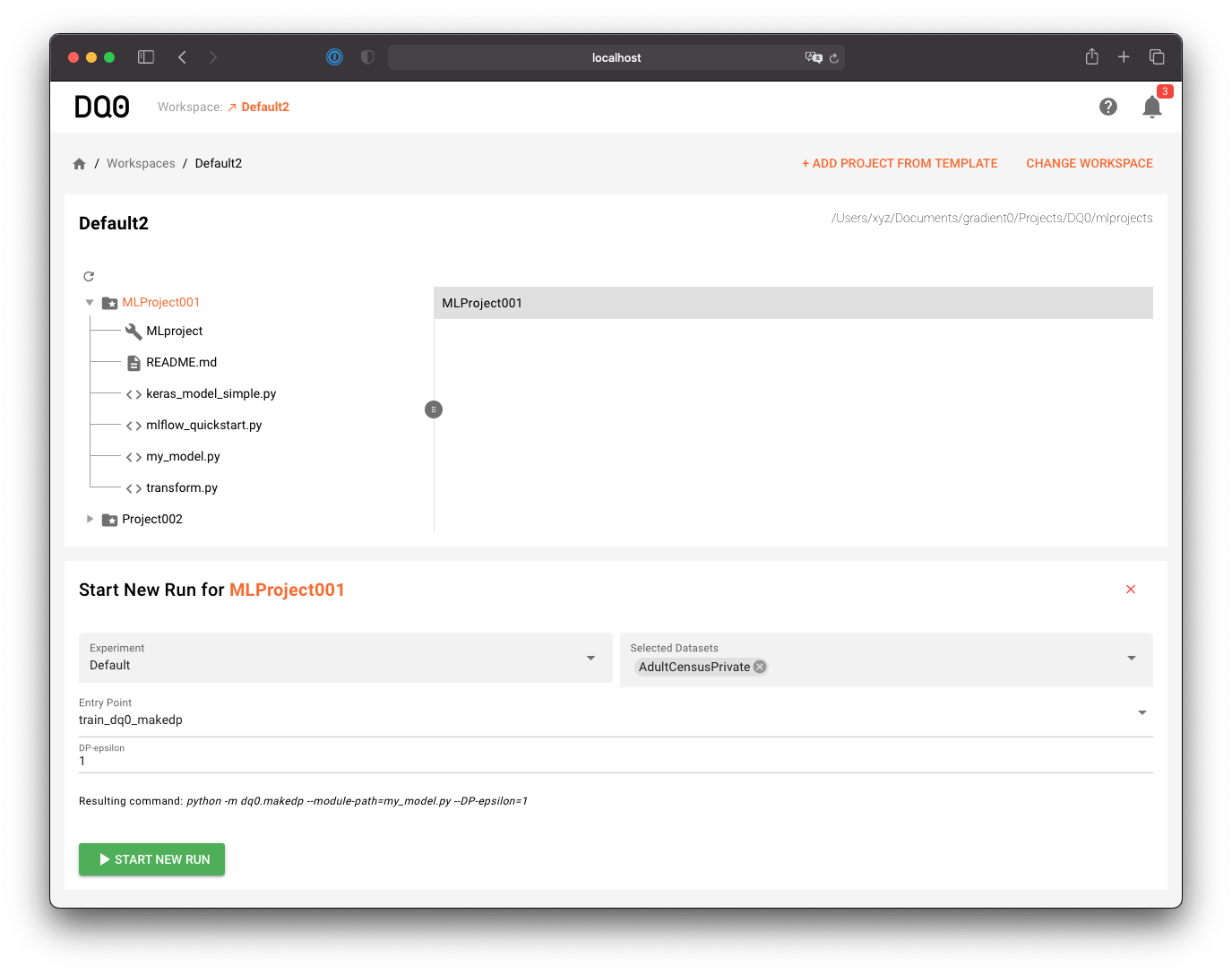
Note: To select a new folder or a new template for a run, you must first remove the current selection by clicking on the cross on the right-hand side of the Start run component.
Refer to the SDK Manual to learn how to define your models for privacy-preserving machine learning in DQ0.
Whenever you want to access sensitive data managed by DQ0, you must use the DQ0 SDK conventions. But generally you are not limited to machine learning or DQ0 privacy analytics. You can run any projects with any code on the platform. On the basic level, the DQ0 instance provides a general purpose compute platform.
The MLproject file in your project folder defines the entry points and parameters for your MLFlow project. Parameters that you add to this file will automatically be included in the "Parameters" section of this screen.
Refer to the MLFlow documentation to learn more about the MLFlow framework.
A filterable and sortable overview of all runs can be found on the run screen accessible via the "Runs" main menu item:
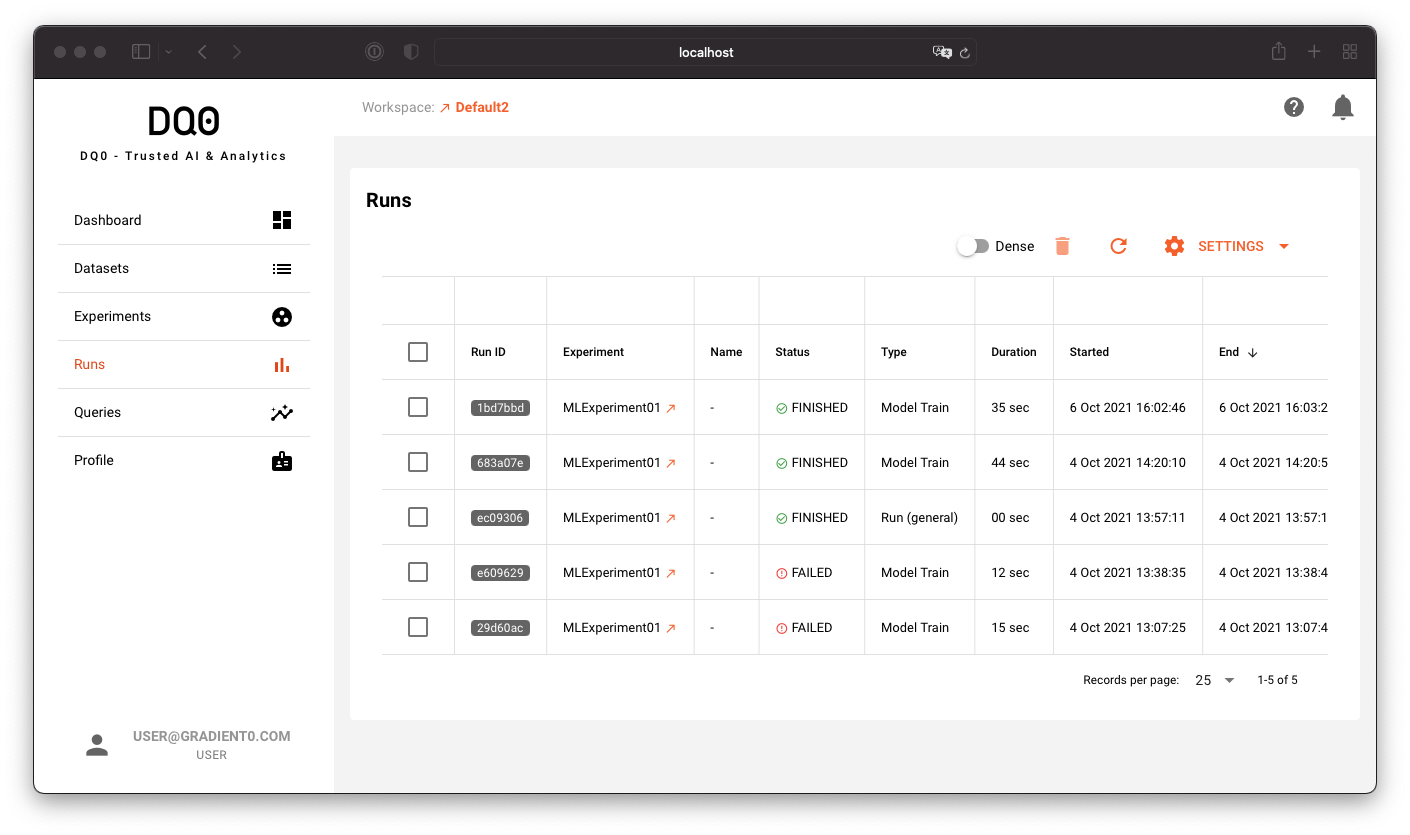
You can customize the run table as described in the next section.
Experiments
Every run in DQ0 belongs to an experiment. Click on the experiments menu item to see a list of all experiments.
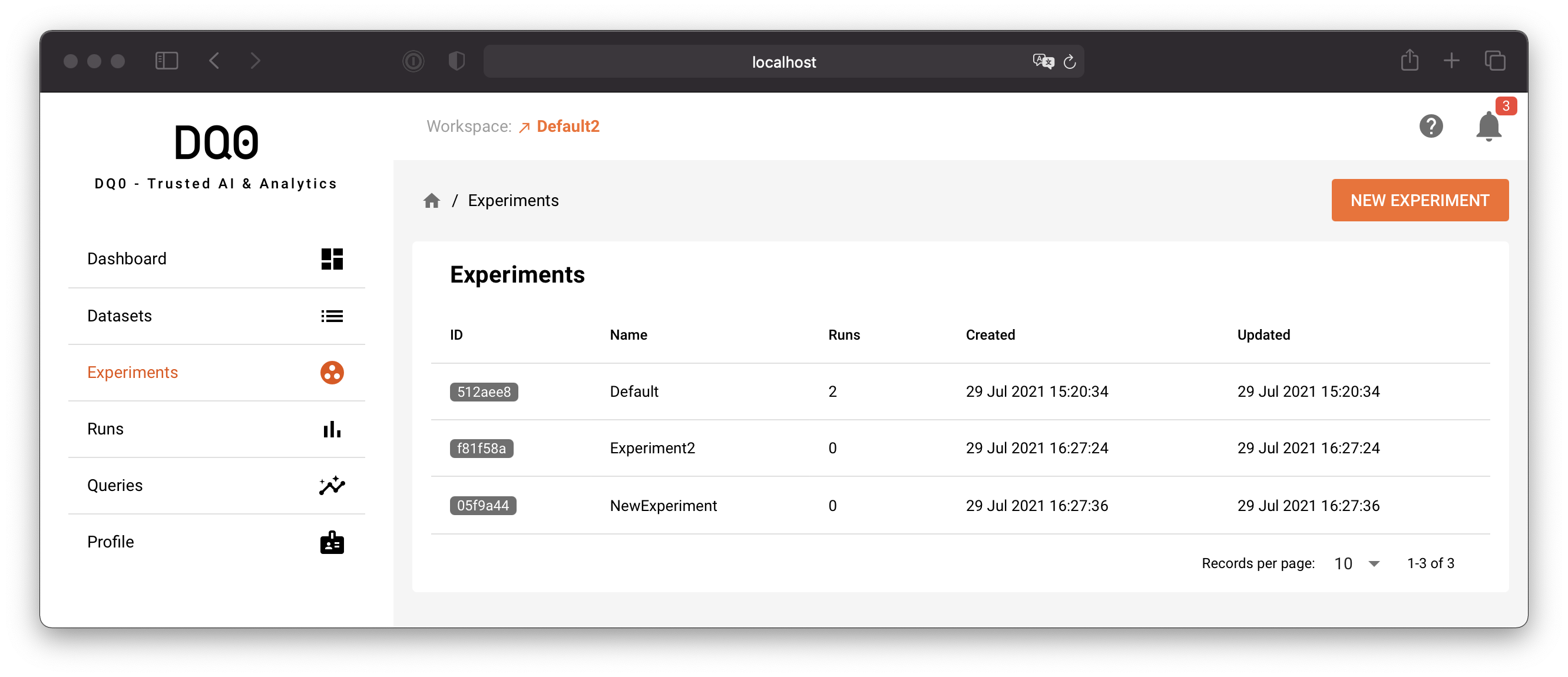
Use the "New Experiment" button to create a new experiment. You can alternatively create new experiments directly in the dropdown field of the new run screen.
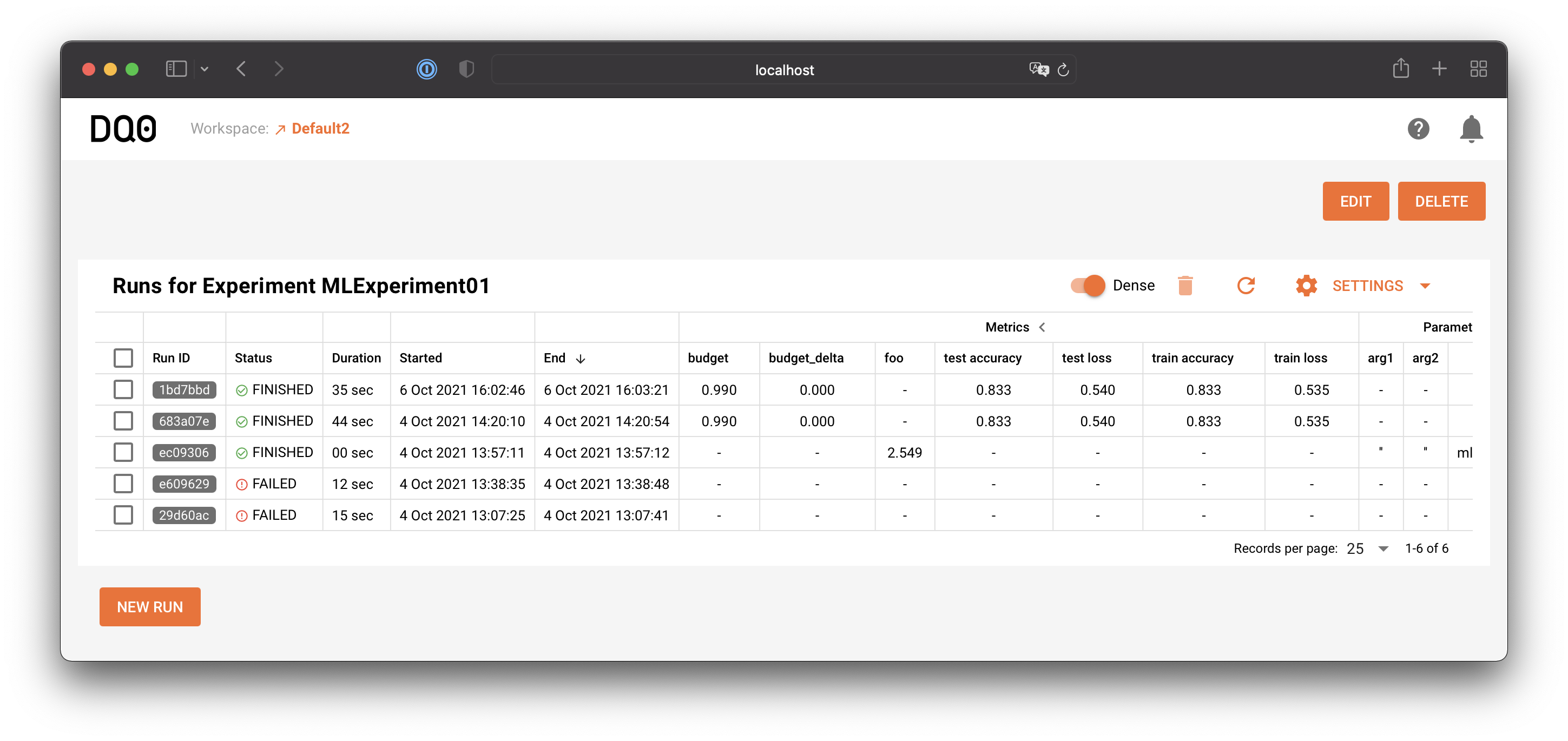
Click on the row of one listed experiment to access the experiment details page. The experiment details page provides a list of all associated runs and looks like this:
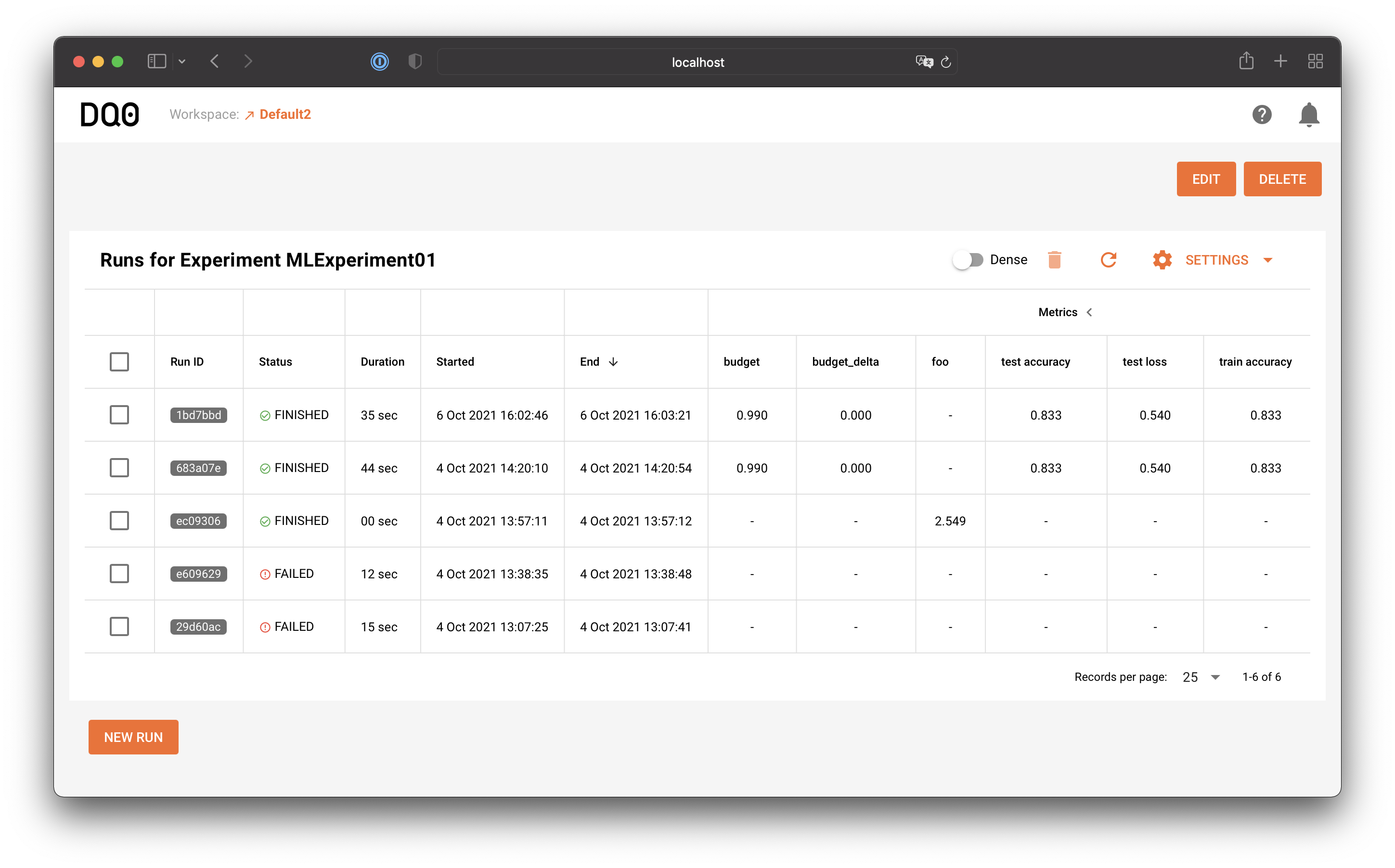
If you want to see more runs on one page you can toggle the "dense mode" button above the table:
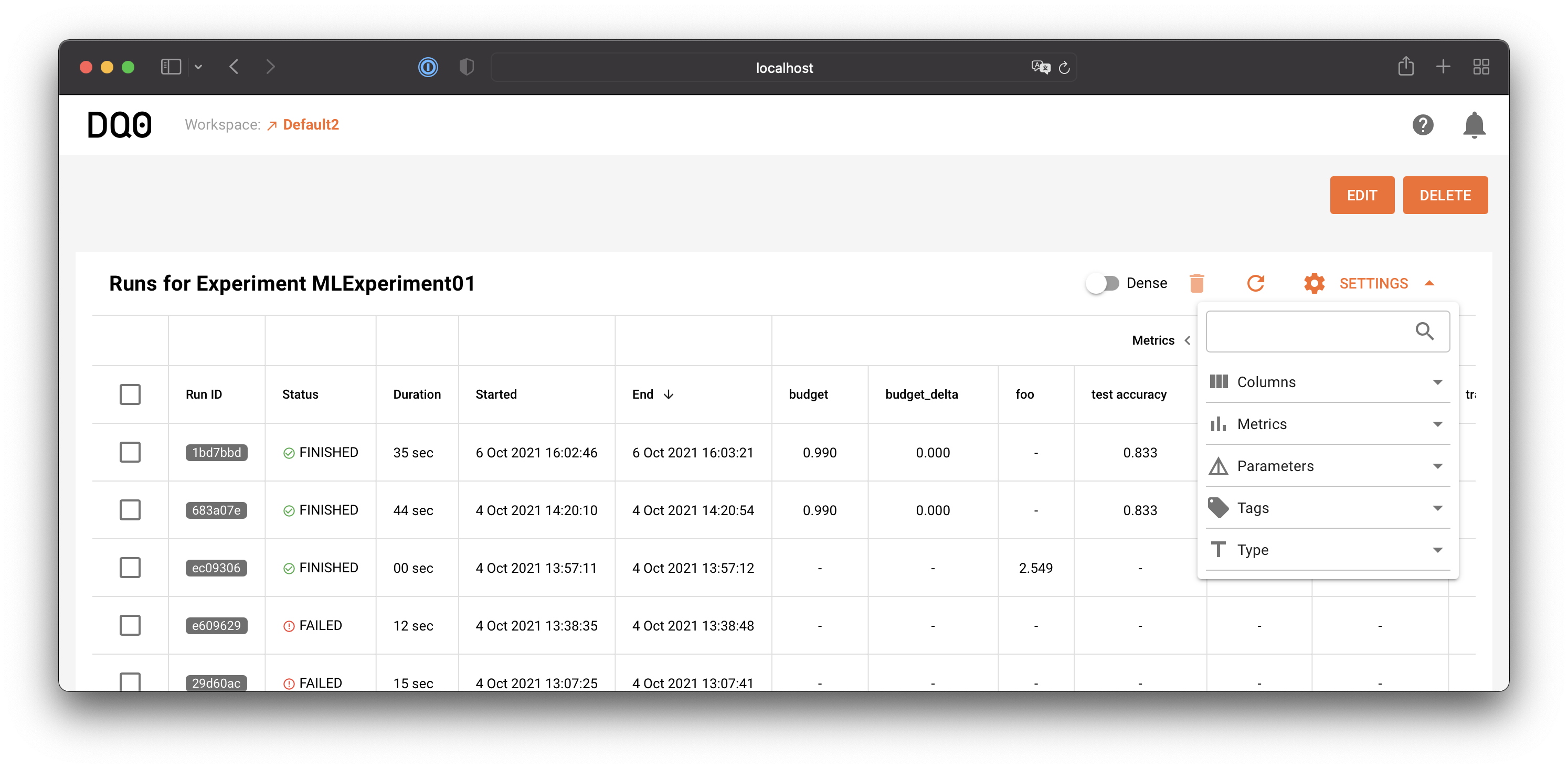
Via the Settings table menu you can customize the run table: hide or show columns, hide or show metrics, parameters, tags, or filter by types:
Run Details
Runs are analytic (or more precisely any compute) jobs executed by the DQ0 platform's service and plugin systems.
The Run Details screen looks like this:
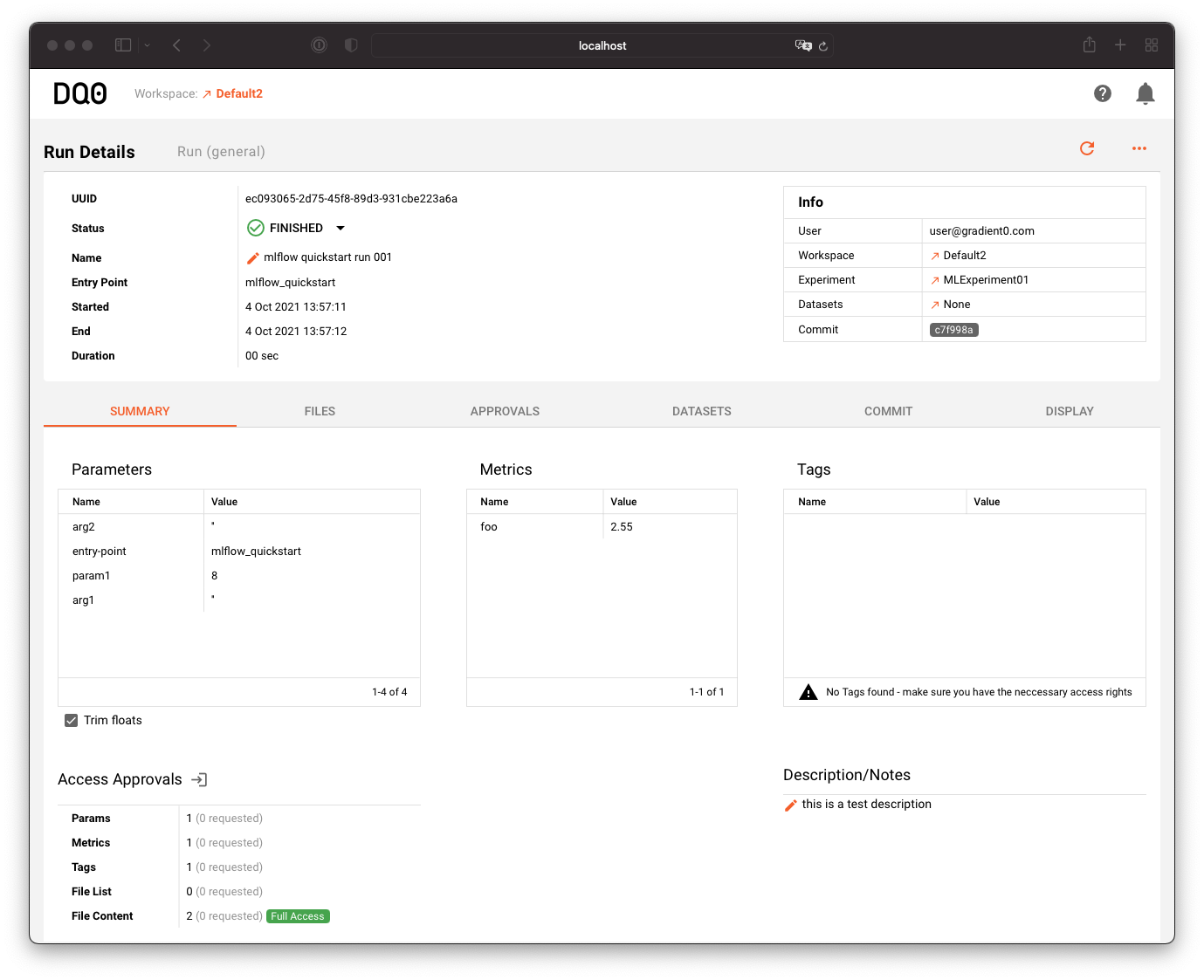
The upper section provides general information about the run, its status, name, mlflow entry point, start and end time as well as information about the corresponding user, workspace, experiment and dataset.
The "Summary" tab provides information about the runs parameters, metrics and tags and the current access status approvals for this run.
In the "Files" tab you can access log files and run artifacts:
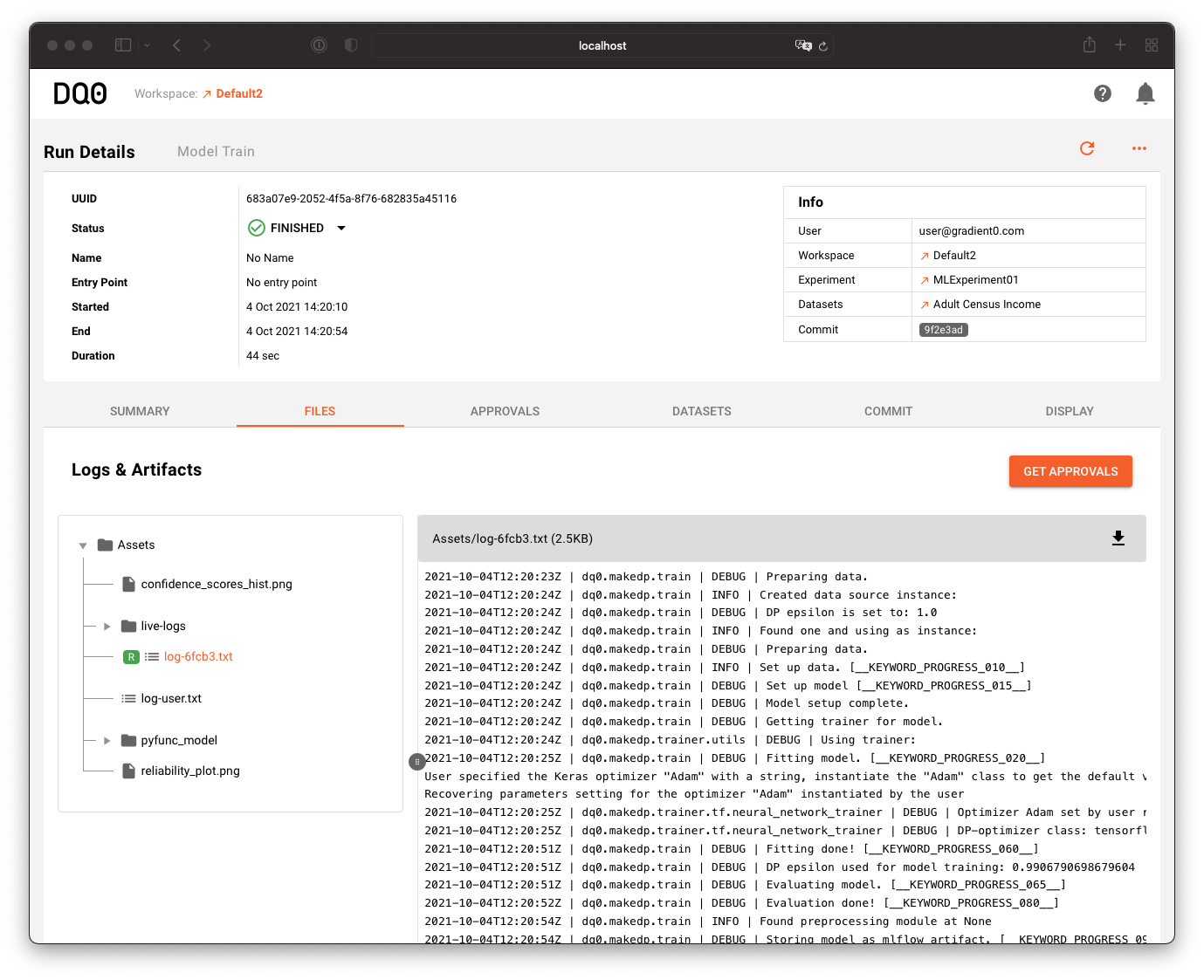
Run artifacts usually contain the results of a computation. In the case of a model training the binary model files are presented in the shown tree structure.
The "Approvals" tab is displaying the requested and granted run approvals. Go to the approval section to learn more about that.
The "Datasets" tab provides information about the used dataset.
The "Commit" tab is presenting the code that was transferred to and executed on the DQ0 compute instance. It is here for your reference to compare your local code with the version that was executed per run. Use the file browser to inspect the files of the runs commit:
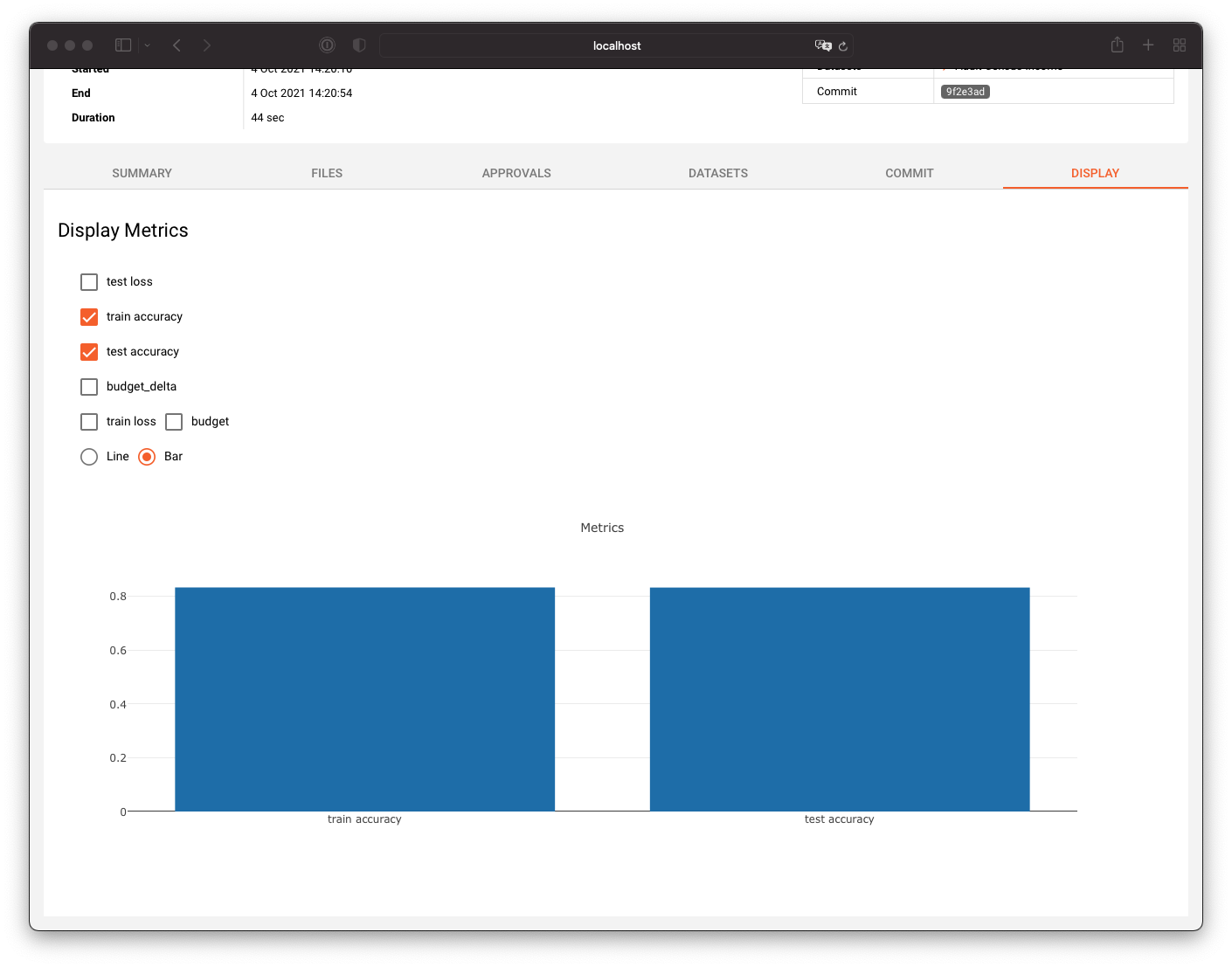
In the "Display" tab you can inspect the runs metrics in a customizable plot: